Introduction
Both the UK and USA guidelines for cord blood selection recommend three and four mismatches as suitable options for patients with high-risk leukemia and for treatment-resistant types of blood cancer. Some of the WMDA member organisations have implemented to run a routine cord search with up to four mismatches as a default.
3 and 4 mismatch searches have now been implemented for Cord searches. Here are some things you need to know:
- In order to minimise unnecessary use of resource-intensive 3 and 4 mismatch cord searches, you first need to have finished
- a 2 mismatch CBU search before you can start a 3 mismatch search
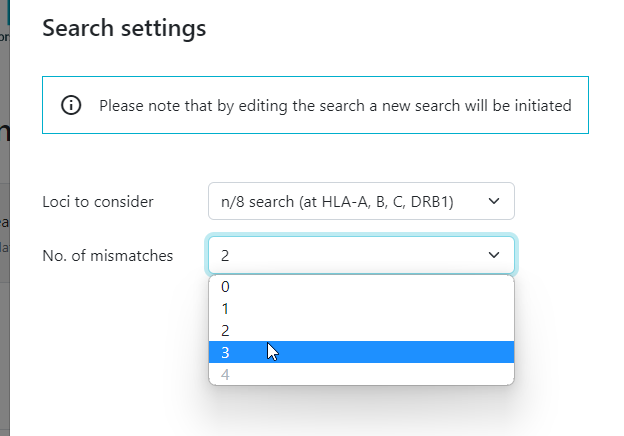
- a 3 mismatch CBU search before you can start a 4 mismatch search
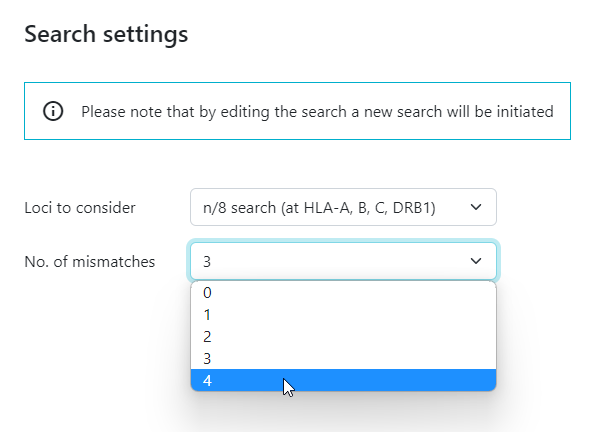
- a 3 mismatch CBU search before you can start a 4 mismatch search
- a 2 mismatch CBU search before you can start a 3 mismatch search
- Just like in the legacy system, no overall match probabilities are calculated and sorting is performed within the match class (i.e. 5/8. 4/8) based on the TNC count or CD34 count (depending on what you have selected. TNC count is the default)
- The number of search results can be bigger than it was when using the legacy system. It is advisable to use filters as the number of results can be great. You can for example filter on the minimum TNC, minimum CD34 or by certain registries or mismatch locations.
Future improvements
As mentioned above, since 3 and 4 mismatch CBU search results do not have any match probabilities calculated, the results are currently sorted within their match class (e.g. 5/8, 4/8) only by TNC or CD34. The Hap-E algorithm in the new Search & Match service returns more potential CBUs than the legacy system. Many of these “extra” CBUs tend to be low probability CBUs that have low resolution or missing typing. This is not actually “wrong” because they are a potential match, but many of these tend to not be good candidate CBUs.
This means that a poorly matched CBUs with high cell dose are at the top of the list and potentially better CBUs with a high enough cell dose are lower. This has always been the case in legacy Search & Match as well, but because of the increased number of valid potential matches, it is a bit harder to find suitable CBUs than the legacy Search & Match.
In an effort to improve the search coordinator's experience when performing 3 and 4 mismatch searches we are currently developing several features that should improve the efficiency of finding suitable CBUs. These are:
- Filter for returning only donors/CBU with typing at C (and/or DQB1).
- Filter on match class so you can go directly to the 5/8 or 4/8 potential matches. Scheduled for delivery December 2022
- Match probability calculation for 3 and 4 mismatches. Scheduled for delivery Q1 of 2023.
- "Score" based sorting for 3 and 4 mismatch results. Scheduled for delivery to production early December 2022. This method is explained below:
Score based sorting of 3 & 4 mismatch search results
In general it is true that the more highly typed a CBU/ donor on a match list is, the higher the probability of a match. As we are currently not able to provide match probabilities and it will take a few months to fully develop, we will use a score based approach. This works in the following way
- Assign a score based on the typed loci and their resolution
- Each locus can have one of the following “resolutions”
- High resolution typing (only one ARD)
- Low or intermediate typing
- No typing
- Each resolution class per locus has a “score”.
- High = 20
- Low or intermediate = 17
- No typing = 0
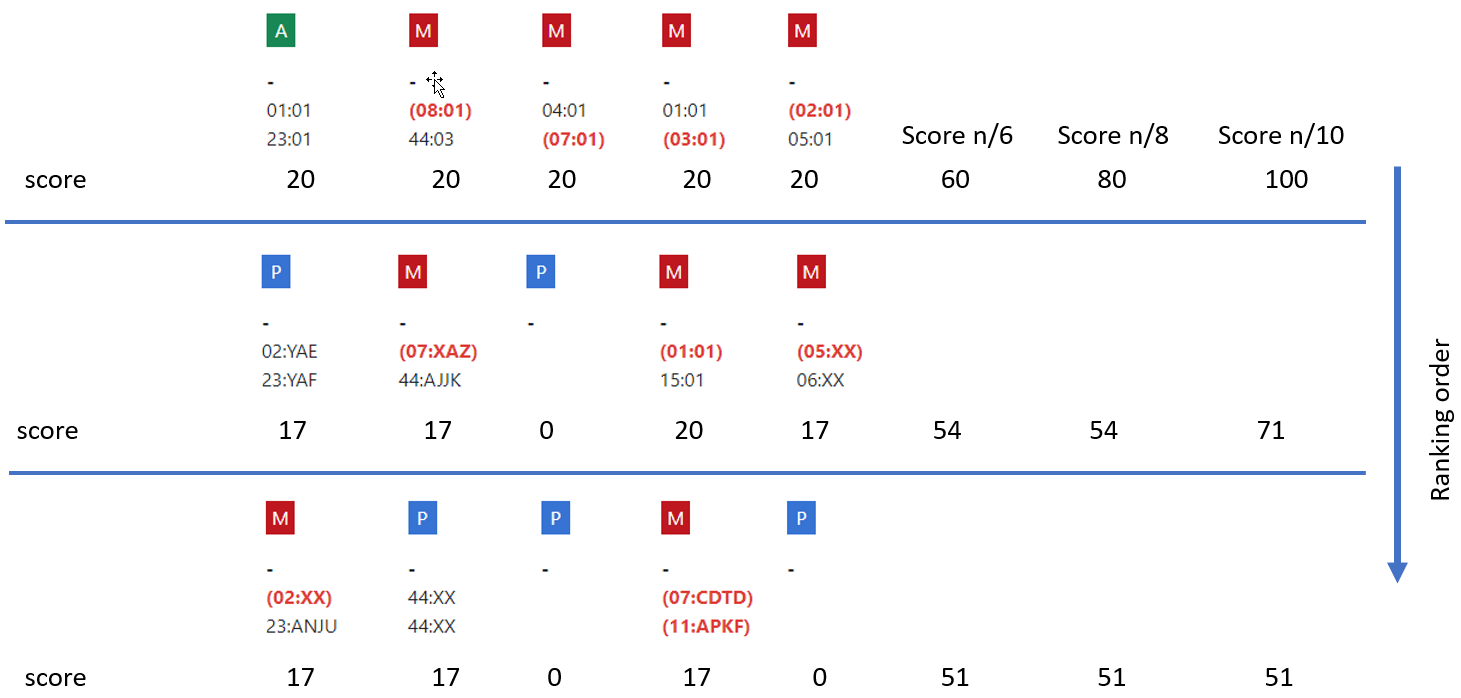
- We sort CBUs based on the sum of the score first and only then by TNC/CD34
- n/6: sum of score at A, B, DRB1
- n/8: sum of score at A, B, C, DRB1
- n/10: sum of score at A, B, C, DRB1 and DQB1
- Sorting for 0 , 1 and 2 mismatches remains unchanged
Because of the way the scores are assigned per locus, a CBU with typing at C when doing an n/8 search will always be ranked higher than a CBU with high resolution typing at 3 loci and no typing at C.
Below you can find some examples.
Match probabilities
Calculation of actual match probabilities would provide a better way of ranking than score-based ranking. Unfortunately this requires quite a lot of work in core elements of the Hap-E algorithm. This therefore needs to be done with great care and needs to be thoroughly tested in order to make sure no part of the Hap-E algorithm is accidentally broken as a result of the added functionality. It therefore cannot be delivered until Q1 of 2023.